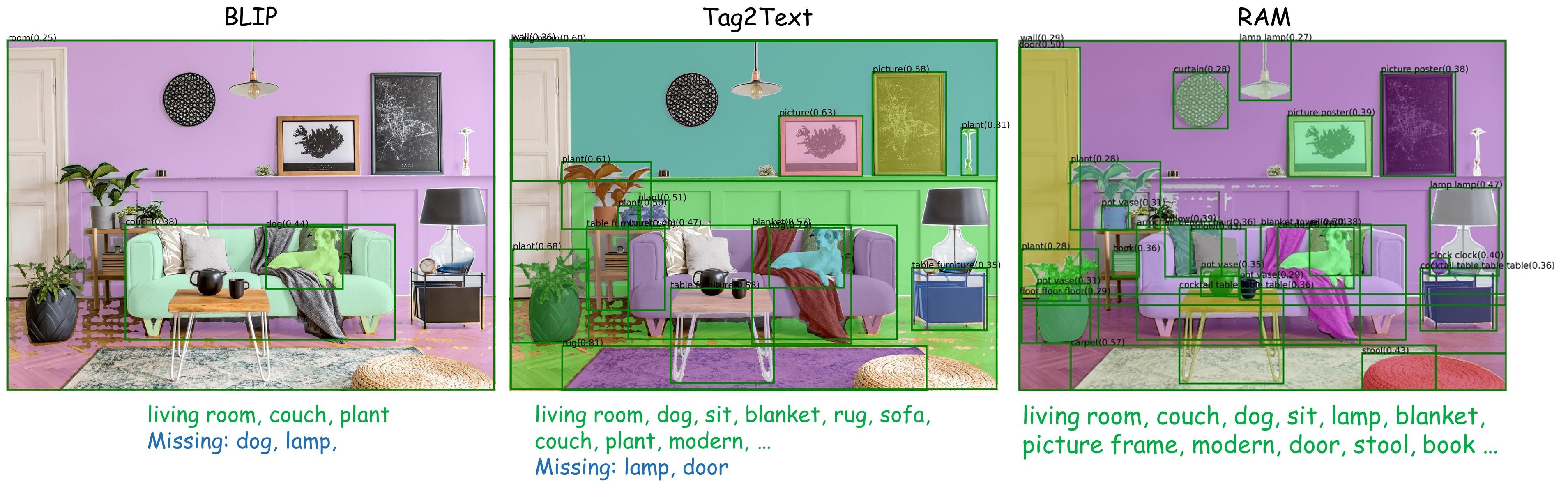
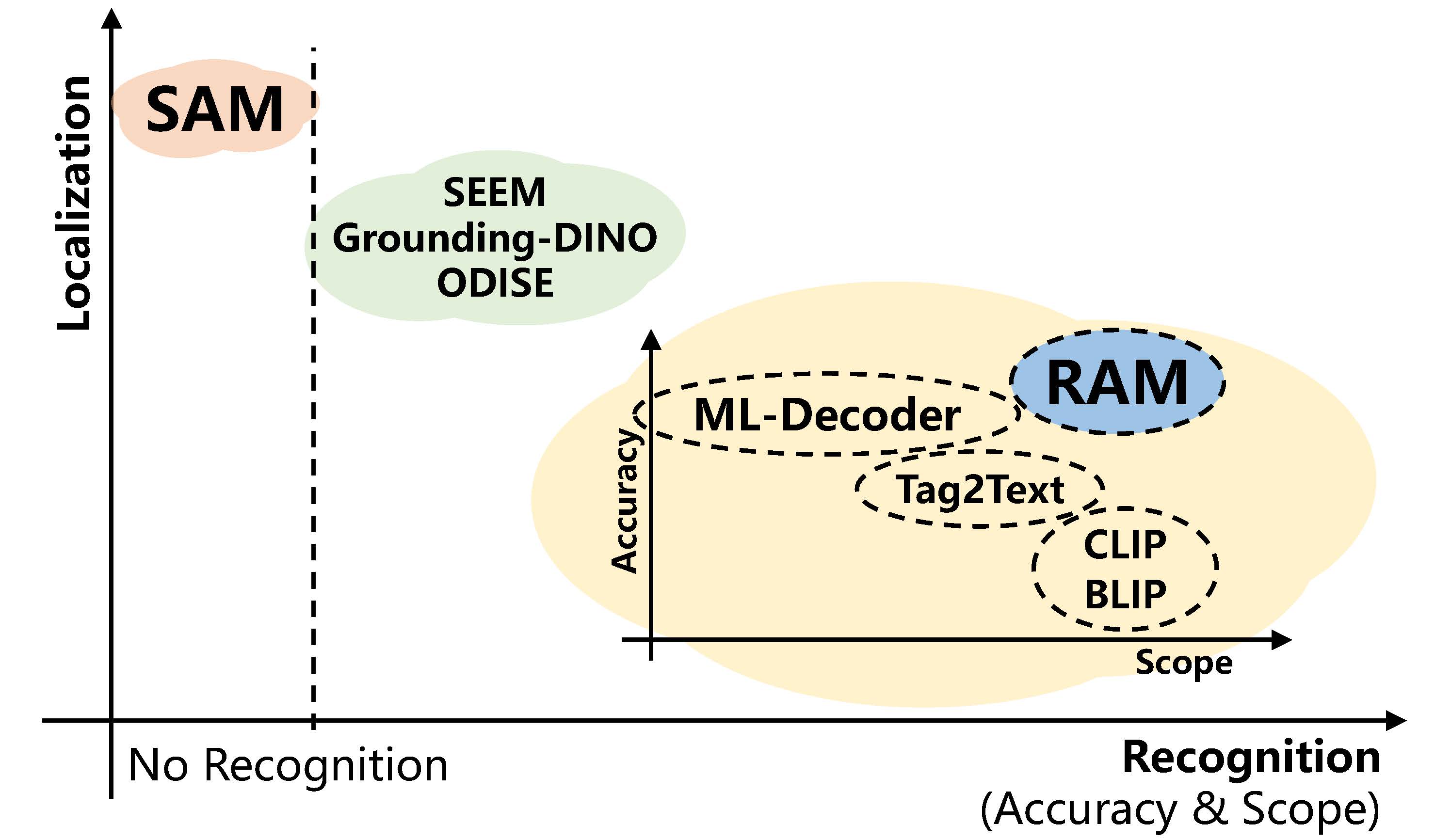
Recognition and localization are two foundation computer vision tasks.
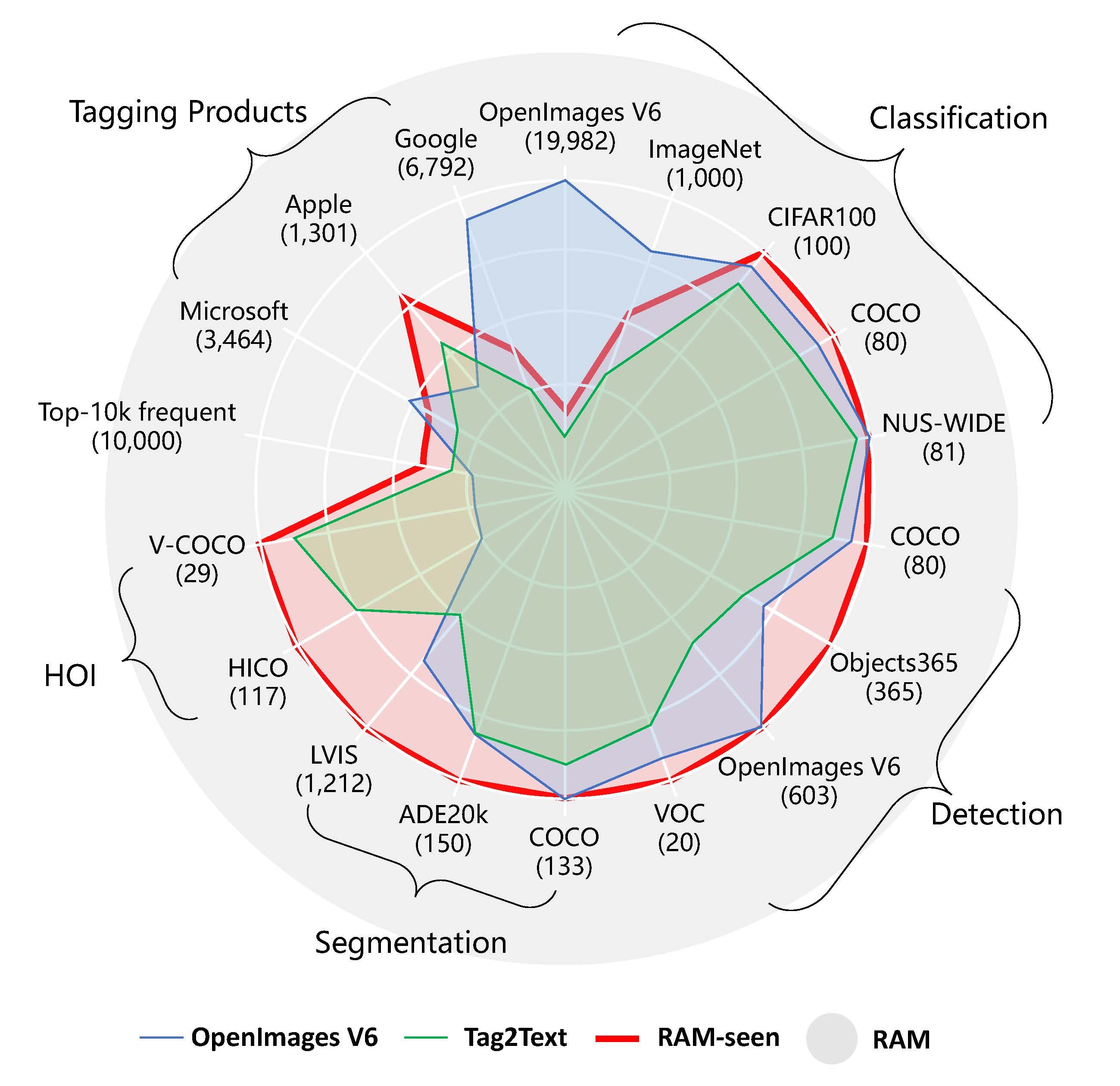
RAM can recognize more valuable tags than other models.

@article{zhang2023recognize,
title={Recognize Anything: A Strong Image Tagging Model},
author={Zhang, Youcai and Huang, Xinyu and Ma, Jinyu and Li, Zhaoyang and Luo, Zhaochuan and Xie, Yanchun and Qin, Yuzhuo and Luo, Tong and Li, Yaqian and Liu, Shilong and others},
journal={arXiv preprint arXiv:2306.03514},
year={2023}
}
@article{huang2023tag2text,
title={Tag2Text: Guiding Vision-Language Model via Image Tagging},
author={Huang, Xinyu and Zhang, Youcai and Ma, Jinyu and Tian, Weiwei and Feng, Rui and Zhang, Yuejie and Li, Yaqian and Guo, Yandong and Zhang, Lei},
journal={arXiv preprint arXiv:2303.05657},
year={2023}}